如何作ECShop指纹识别版本判断代码
发布时间:12/03 来源: 浏览:
关键词:
ECShop指纹识别只是从以下三个入手:
1.meta数据元识别
2.intext:powered by ECShop
3.robots.txt
我们打开一个ECShop网站,看看页面中这几方面的特征。
1.我们现在看看meta标签中有什么特征。下面是我截取的一段HTML。

可以看到,这个网站对meta标签没有处理,保留了ECShop的原始meta。网站是ECShop及其版本是2.7.2。此处也是做版本识别的地方。
2.再往下查看网页
我们发现在footer中有Powered by ECShop
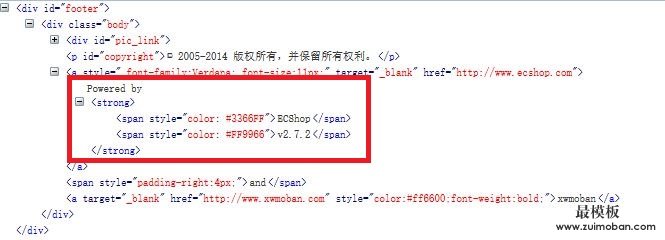
可以看到,这个网站对ECShop的footer没有修改,保留了ECShop的原始的footer,此处我们可以识别ECShop及其版本。由于一般网站修改此处的较多,这里就不做版本识别了。
3.对robots.txt内容的检查
robots.txt文件是一个文本文件。robots.txt是一个协议,而不是一个命令。robots.txt是搜索引擎中访问网站的时候要查看的第一个文件。robots.txt文件告诉蜘蛛程序在服务器上什么文件是可以被查看的。
当一个搜索蜘蛛访问一个站点时,它会首先检查该站点根目录下是否存在robots.txt,如果存在,搜索机器人就会按照该文件中的内容来确定访问的范围;如果该文件不存在,所有的搜索蜘蛛将能够访问网站上所有没有被口令保护的页面。
那么这可以被我们利用,以识别ECShop,看下面截图,我们发现有些文件是ECShop特有的,比如:/affiche.php、/good_script.php、/feed.php。那么,如果存在这几个特征,我们可以基本确定这就是一个ECShop CMS了。
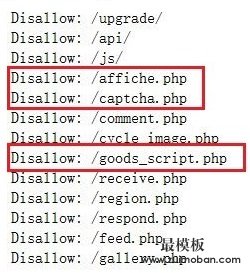
将ECShop指纹单独保存为识别字典
ecshop_feature.py
[python] view plaincopy
- #coding=utf-8
- '''''
- web-fingerprint plugin
- 1. robots.txt detecting
- 2. Powered by Ecshop detecting
- 3.meta
- '''
- matches = {
- 'robots_for_ecshop':
- ["Disallow: /cert/",
- "Disallow: /templates/",
- "Disallow: /themes/",
- "Disallow: /upgrade/",
- "Disallow: /affiche.php",
- "Disallow: /cycle_image.php",
- "Disallow: /goods_script.php",
- "Disallow: /region.php",
- "Disallow: /feed.php"],
- 'intext':['<a target="_blank" style=" font-family:Verdana; font-size:11px;">Powered by <strong><span style="color: #3366FF">ECShop</span> <span style="color: #FF9966">v2.7.',
- '<a href="http://www.ecshop.com/license.php?product=ecshop_b2c&url='],
- 'meta':['ECSHOP v2.7.3','ECSHOP v2.7.2','ECSHOP v2.7.1','ECSHOP v2.7.0','ECSHOP v2.6.2','ECSHOP'],
- 'title':['Powered by ECShop',]
- }
[python] view plaincopy
- #coding=utf-8
- import re
- from ecshop_feature import matches
- import urllib2
- '''''
- Ecshop 指纹识别
- 1.meta数据元识别
- 2.intext识别
- 3.robots.txt识别
- '''
- class EcshopDetector():
- '''''构造方法,将域名改成URL'''
- def __init__(self,url):
- def handler(signum, frame):
- raise AssertionError
- if url.startswith("http://"):
- self.url = url
- else:
- self.url = "http://%s" % url
- try:
- httpres = urllib2.urlopen(self.url, timeout = 5)
- self.r = httpres
- self.page_content = httpres.read()
- except Exception, e:
- self.r = None
- self.page_content = None
- '''''识别meta标签,版本识别'''
- def meta_detect(self):
- if not self.r:
- return (False,None)
- pattern = re.compile(r'<meta name=".*?" content="(.+)" />')
- infos = pattern.findall(self.page_content)
- if infos:
- for x in infos:
- for i in range(0,5):
- if x == matches['meta'][i]:
- return (True, '%s' %matches['meta'][i])
- break
- if x == matches['meta'][5]:
- return (True,None)
- break
- return (False,None)
- else:
- return (False,None)
- '''''ecshop robots.txt,考虑到其他网站也可能用robots.txt中文件名,故必须有两个以上文件名相同'''
- def robots_ecshop_detect(self):
- if not self.r:




