终于了解 MySQL 索引要用 B+tree ,并且还这么快
mysql教程栏目介绍懂得索引的B+tree。

免费引荐:mysql教程(视频)
前言
当你此刻碰到了一条慢 SQL 需要停止优化时,你第一时间能想到的优化手段是啥?
大部分人第一反响大概都是增加索引,在大多数状况下面,索引能够将一条 SQL 语句的查询效力提高几个数目级。
索引的本质:用于快速查寻记载的一种数据构造。
索引的常用数据构造:
- 二叉树
- 红黑树
- Hash 表
B-tree(B树,并不叫什么B减树)B+tree
数据构造图形化网址:https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
索引查询
大家知道 select * from t where col = 88 这么一条 SQL 语句假如不走索引停止查寻的话,正常地查就是全表扫描:从表的第一行记载开端逐行寻,把每一行的 col 字段的值和 88 停止对照,这明显效力是很低的。

而假如走索引的话,查询的流程就完全不一样了(假设此刻用一棵均衡二叉树数据构造储备我们的索引列)
此时该二叉树的储备构造(Key - Value):Key 就是索引字段的数据,Value 就是索引所在行的磁盘文件地址。
当最后寻到了 88 的时候,就可以把它的 Value 对应的磁盘文件地址拿出来,然后就直接去磁盘上去寻这一行的数据,这时候的速度就会比全表扫描要快许多。

但实际上 MySQL 底层并没有用二叉树来储备索引数据,是用的 B+tree(B+树)。
为什么不采纳二叉树
假设此时用一般二叉树记载 id 索引列,我们在每插入一行记载的同时还要保护二叉树索引字段。
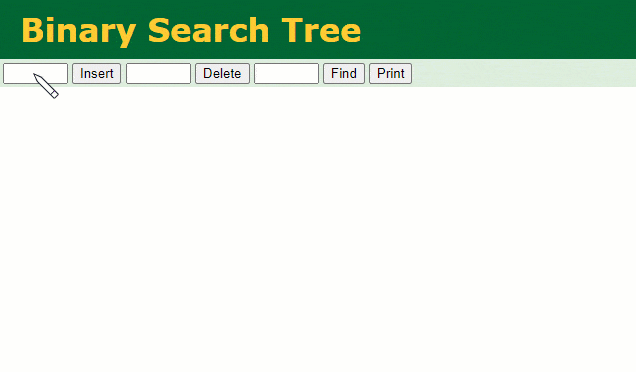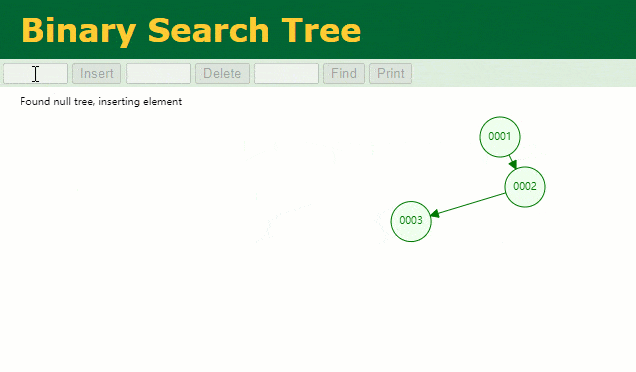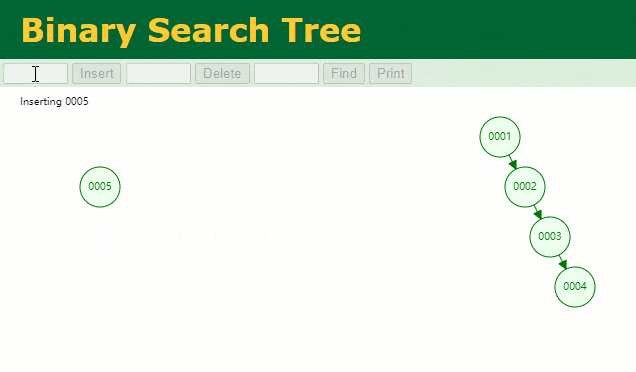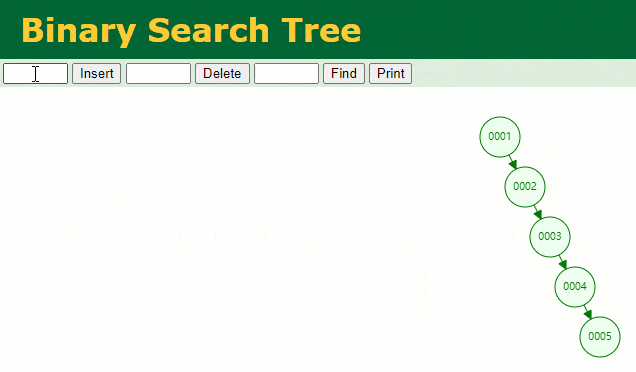
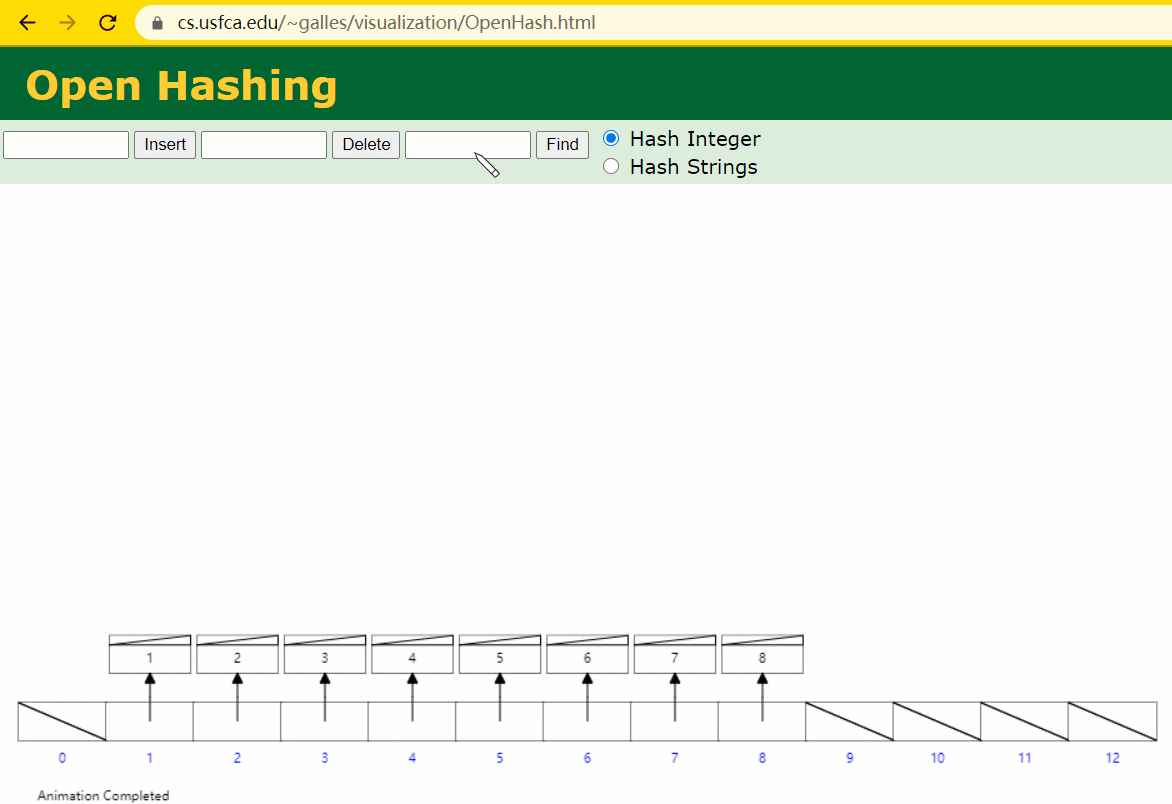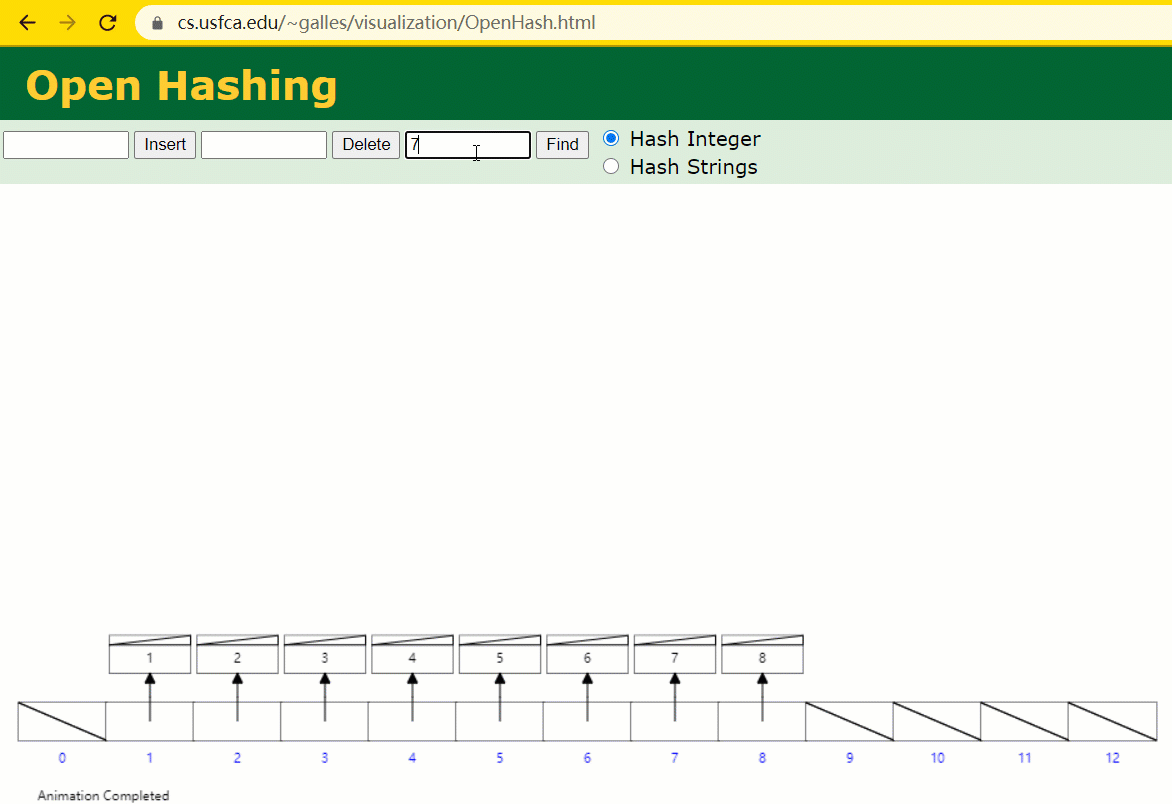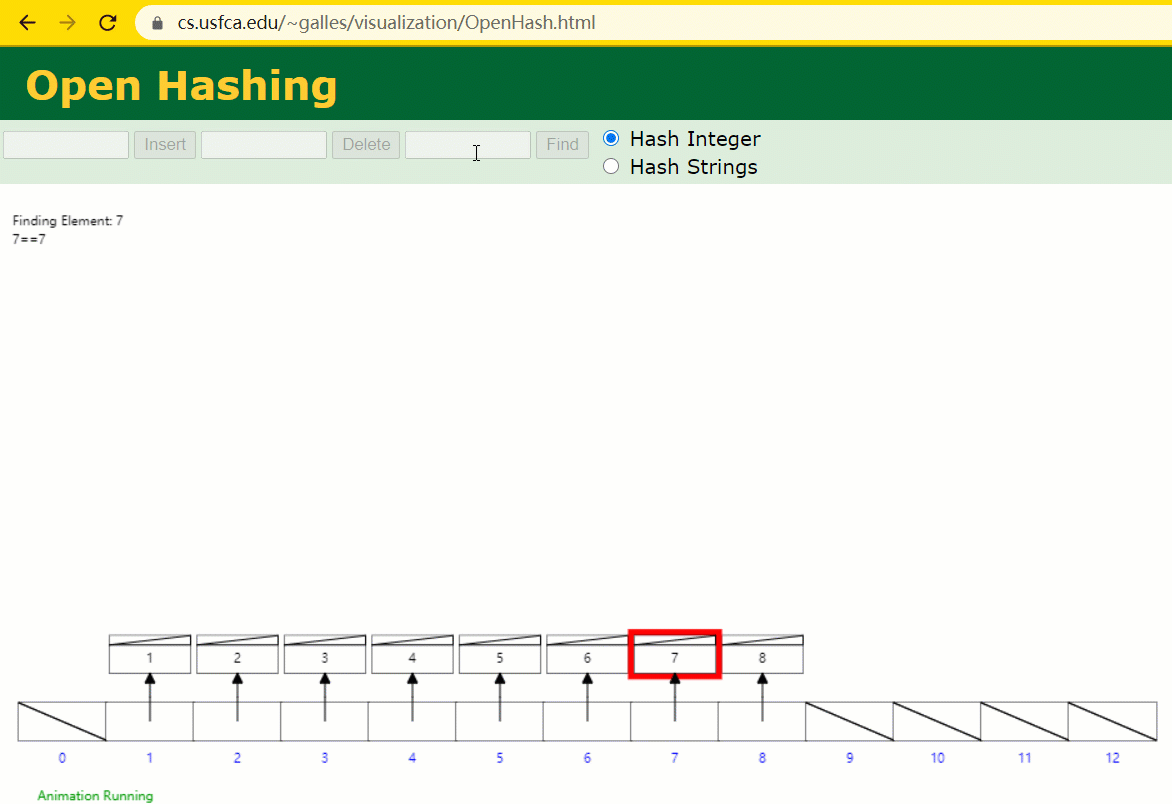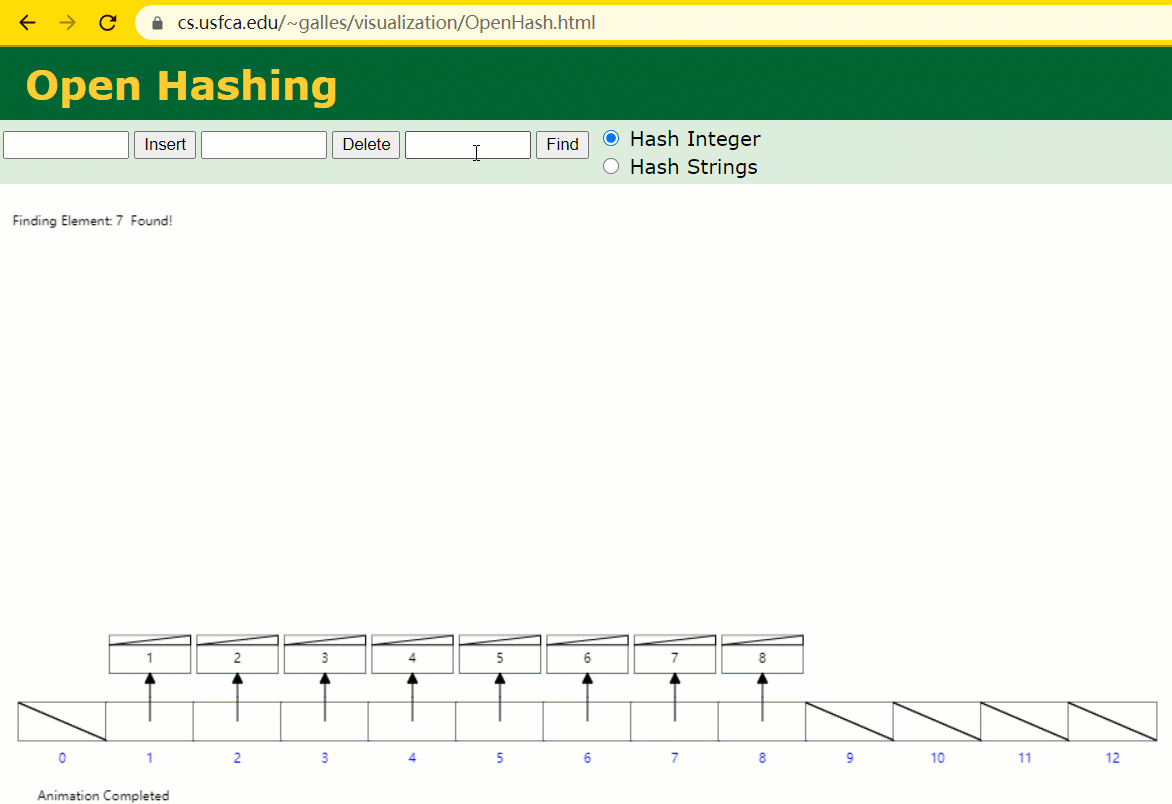
此时当我要寻 id = 7 的那条数据时,它的查寻历程如下:
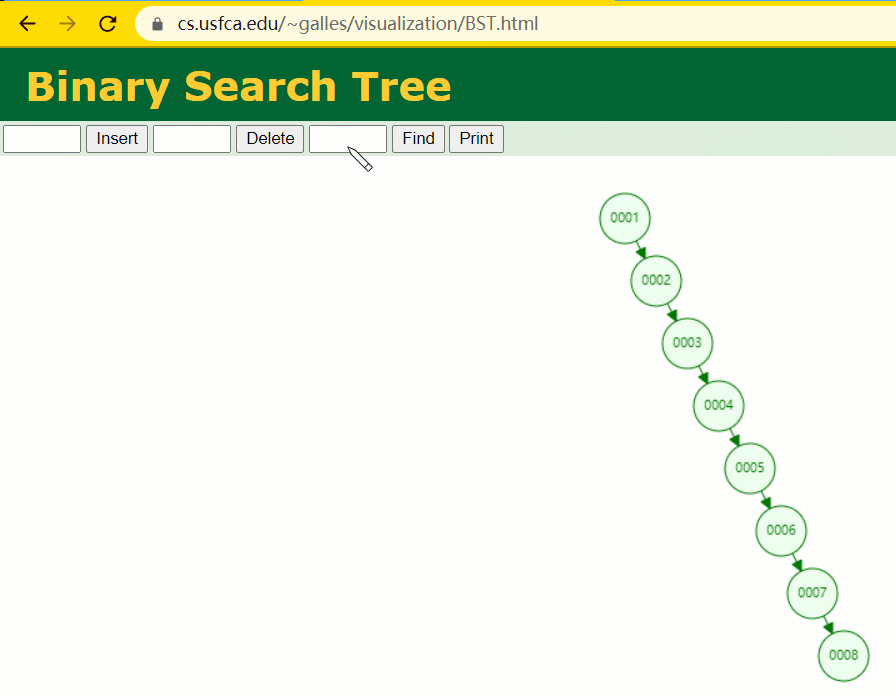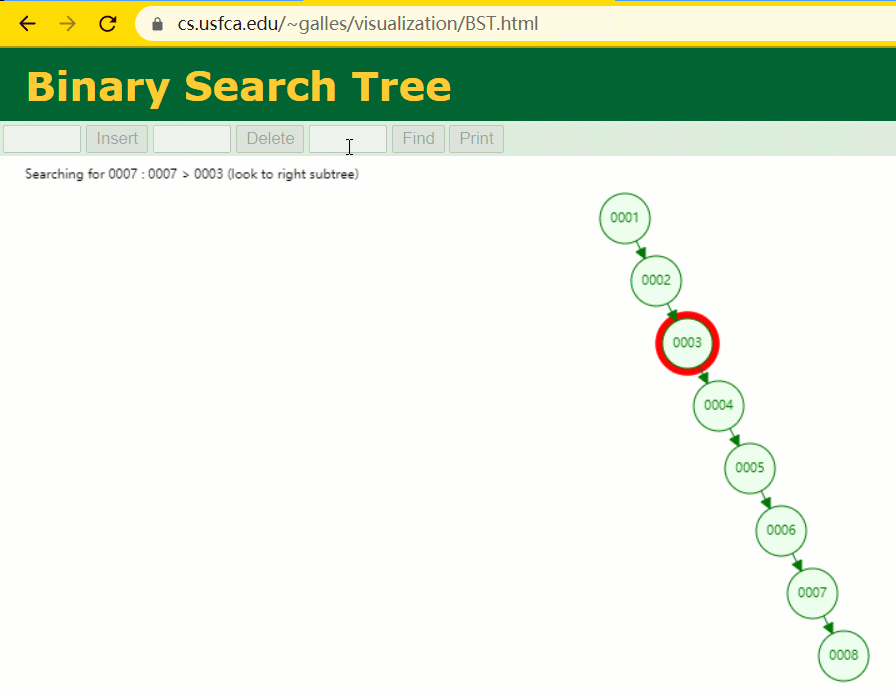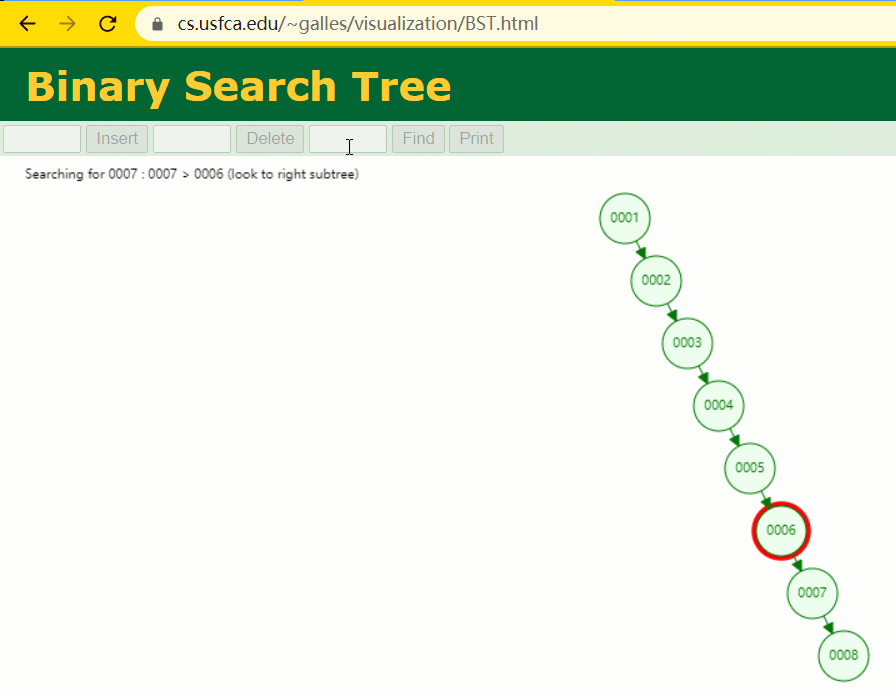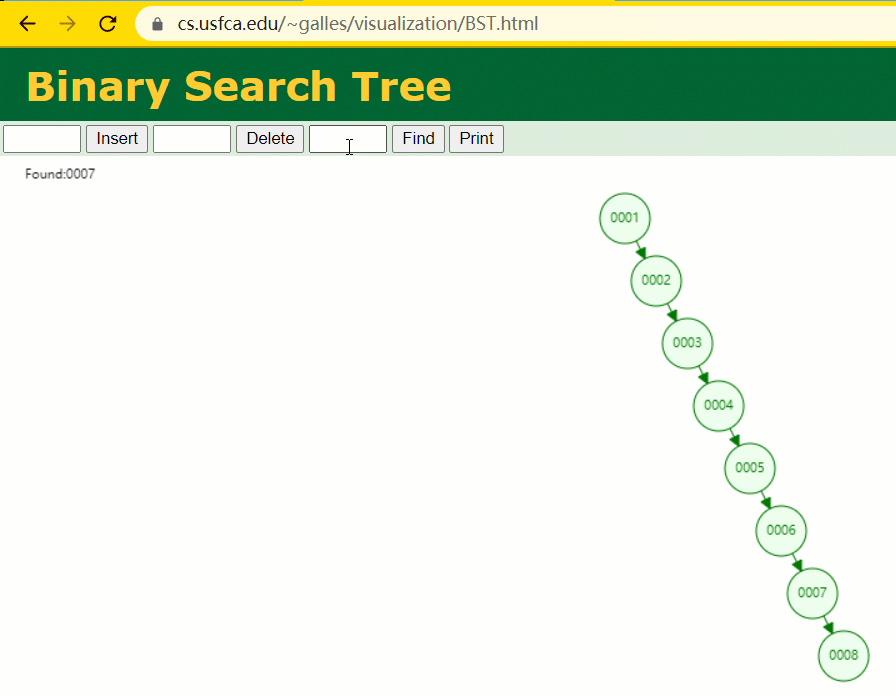
此时寻 id = 7 这一行记载时寻了 7 次,和我们全表扫描也没什么很大不同。不言而喻,二叉树关于这种顺次递增的数据列其实是不适合作为索引的数据构造。
为什么不采纳 Hash 表
Hash 表:一个快速搜索的数据构造,搜索的时间复杂度 O(1)
Hash 函数:将一个任意类型的 key,可以转换成一个 int 类型的下标
假设此时用 Hash 表记载 id 索引列,我们在每插入一行记载的同时还要保护 Hash 表索引字段。

这时候开端查寻 id = 7 的树节点仅寻了 1 次,效力非常高了。
但 MySQL 的索引仍然不采纳能够精准定位的Hash 表。由于它不适用于范畴查询。
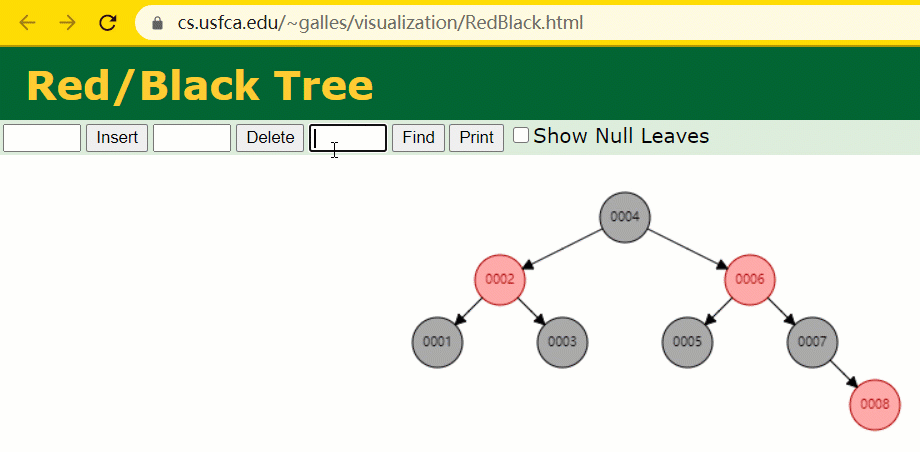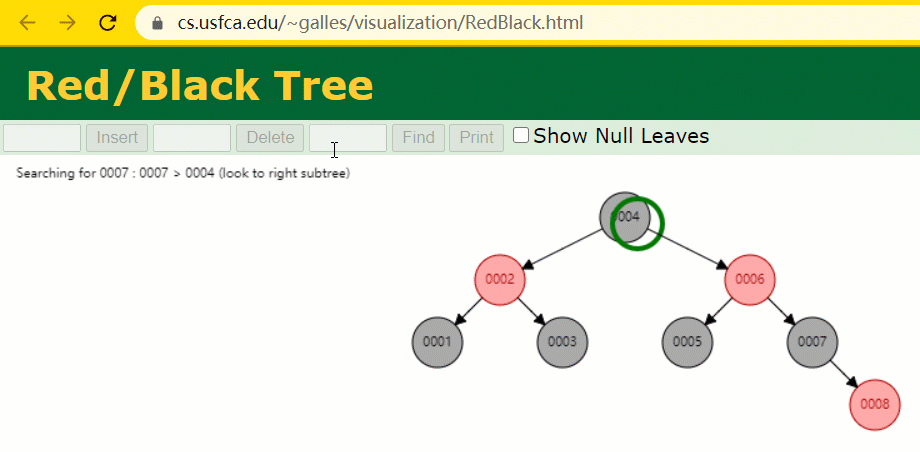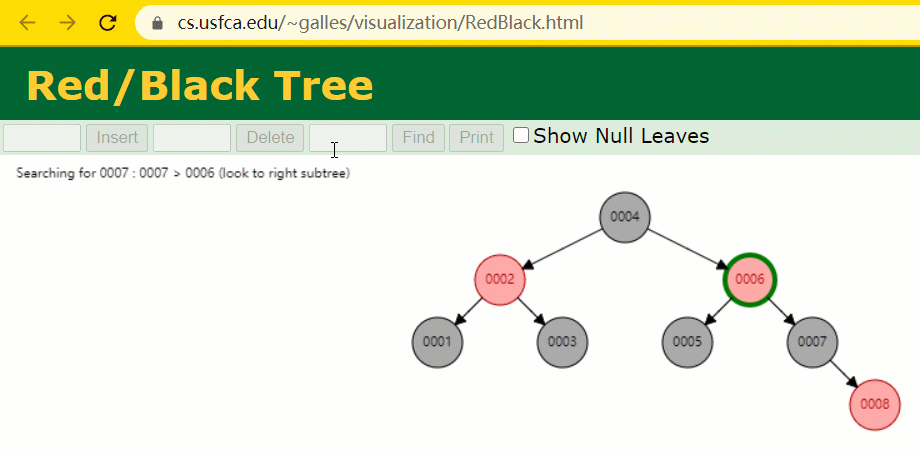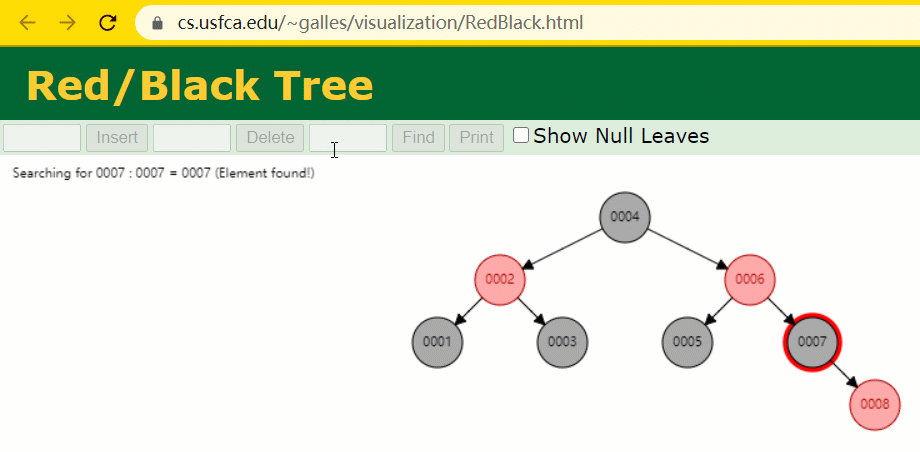
为什么不采纳红黑树
红黑树是一种特化的 AVL树(均衡二叉树),都是在停止插入和删除操纵时通过特定操纵保持二叉查寻树的均衡;
若一棵二叉查寻树是红黑树,则它的任一子树必为红黑树。
假设此时用红黑树记载 id 索引列,我们在每插入一行记载的同时还要保护红黑树索引字段。

插入历程中会发明它与一般二叉树不一样的是当一棵树的摆布子树高度差 > 1 时,它会停止自旋操纵,保持树的均衡。
这时候开端查寻 id = 7 的树节点只寻了 3 次,比所谓的一般二叉树还是要更快的。
但 MySQL 的索引仍然不采纳能够准确定位和范畴查询都优异的红黑树。
由于当 MySQL 数据量很大的时候,索引的体积也会很大,大概内存置不下,所以需要从磁盘上停止相关读写,假如树的层级太高,则读写磁盘的次数(I/O交互)就会越多,机能就会越差。
B-tree
红黑树当前的独一不足点就是树的高度不成控,所以此刻我们的切入点就是树的高度。
当前一个节点是只分配了一个储备 1 个元素,假如要操纵高度,我们就可以把一个节点分配的空间更大一点,让它横向储备多个元素,这个时候高度就可控了。这么个革新历程,就变成了
B-tree。

B-tree 是一颗绝对均衡的多路树。它的构造中还有两个概念
度(Degree):一个节点具有的子节点(子树)的数目。(有的地方是以度来说明
B-tree的,这里说明一下)阶(order):一个节点的子节点的最大个数。(平常用 m 表示)
关键字:数据索引。
一棵 m 阶 B-tree 是一棵均衡的 m 路搜索树。它大概是空树,或者知足以下特点:
除根节点和叶子节点外,其它每个节点至少有 个子节点;
为 m / 2 然后向上取整
每个非根节点所包括的关键字个数 j 知足: - 1 ≤ j ≤ m - 1;
节点的关键字从左到右递增摆列,有 k 个关键字的非叶子节点恰好有 (k + 1) 个子节点;
所有的叶子结点都位于统一层。
名字取义(题外话,轻松一下)
以下摘自维基百科
鲁道夫・拜尔(Rudolf Bayer)和 艾华・M・麦克雷(Ed M. McCreight)于1972年在波音研讨实验室(Boeing Research Labs)工作时创造了 B-tree,但是他们没有说明 B 代表什么意义(假如有的话)。
道格拉斯・科默尔(Douglas Comer)说明说:两位作者从来都没说明过 B-tree 的原始意义。我们大概觉得 balanced, broad 或 bushy 大概适合。其别人倡议字母 B 代表 Boeing。源自于他的资助,不外,看起来把 B-tree 当作 Bayer 树更适宜些。
高德纳(Donald Knuth)在他1980年5月发布的题为 "CS144C classroom lecture about disk storage and B-trees" 的论文中猜测了 B-tree 的名字取义,提出 B 大概意味 Boeing 或者 Bayer 的名字。
查寻
B-tree 的查寻其实和二叉树很类似:
二叉树是每个节点上有一个关键字和两个分支,B-tree 上每个节点有 k 个关键字和 (k + 1) 个分支。
二叉树的查寻只思考向左还是向右走,而 B-tree 中需要由多个分支决议。
B-tree 的查寻分两步:
- 第一查寻节点,由于
B-tree平常是在磁盘上储备的所以这步需要停止磁盘IO操纵; - 查寻关键字,当寻到某个节点后将该节点读入内存中然后通过次序或者折半查寻来查寻关键字。若没有寻到关键字,则需要推断大小来寻到适宜的分支连续查寻。
操纵流程
此刻需要查寻元素:88
第一次:磁盘IO

第二次:磁盘IO
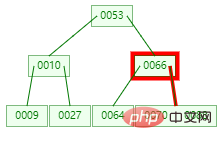
第三次:磁盘IO
然后这有一次内存比对,离别跟 70 与 88 比对,最后寻到 88。

从查寻历程中发明,B-tree 比对次数和磁盘IO的次数其实和二叉树相差不了多少,这么看来并没有什么优势。
但是细心一看会发明,比对是在内存中完成中,不触及到磁盘IO,耗时可以忽略不计。
别的 B-tree 中一个节点中可以存置许多的关键字(个数由阶决议),雷同数目的关键字在 B-tree 中生成的节点要远远少于二叉树中的节点,相差的节点数目就等同于磁盘IO的次数。这样抵达必然数目后,机能的差别就闪现出来了。
插入
当 B-tree 要停止插入关键字时,都是直接寻到叶子节点停止操纵。
- 按照要插入的关键字查寻到待插入的叶子节点;
- 由于一个节点的子节点的最大个数(阶)为 m,所以需要推断当前节点关键字的个数可否小于 (m - 1)。
- 是:直接插入
- 否:发生节点分裂,以节点的中心的关键字将该节点分为摆布两部分,中心的关键字放到父节点中即可。
操纵流程
比方我们此刻需要在 Max Degree(阶)为 3 的 B-tree 插入元素:72
查寻待插入的叶子节点

节点分裂:原本应当和 [70,88] 在统一个磁盘块上,但是当一个节点有 3 个关键字的时候,它就有大概有 4 个子节点,就超越了我们所定义限制的最大度数 3,所以此时必需停止分裂:以中心关键字为界将节点一分为二,发生一个新节点,并把中心关键字上移到父节点中。
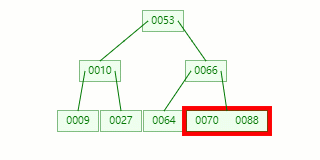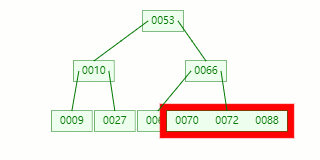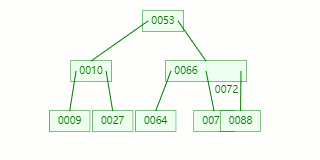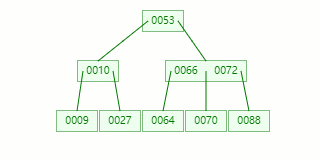
Tip : 傍边间关键字有两个时,平常将左关键字停止上移分裂。
删除
删除操纵就会比查寻和插入要费事一些,由于要被删除的关键字大概在叶子节点上,也大概不在,并且删除后还大概致使 B-tree 的不服衡,又要停止合并、扭转等操纵去保持整棵树的均衡。
随意拿棵树(5 阶)举例子
以上就是终于懂得 MySQL 索引要用 B+tree ,并且还这么快的具体内容,更多请关注百分百源码网其它相关文章!




