PHP联合MySQL实现千万级数据处置
引荐:《PHP视频教程》
mysql分表思绪

一张一亿的订单表,可以分成五张表,这样每张表就只要两千万数据,分担了本来一张表的压力,分表需要按照某个前提停止分,这里可以按照地区来分表,需要一个中心件来操纵到底是去哪张表去寻到本人想要的数据。
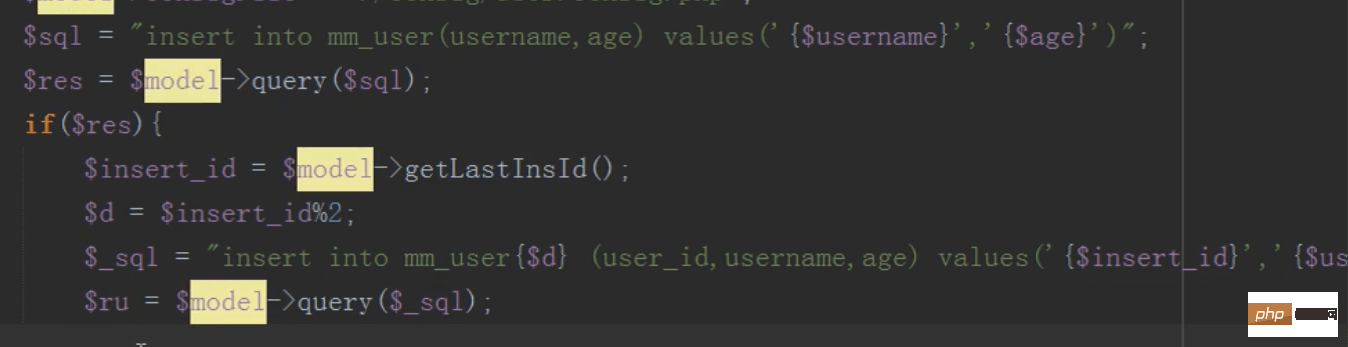
中心件:按照主表的自增id作为中心件(什么样的字段适合做中心件?要具备独一性)
如何分发?主表插入之后返回一个id,按照这个id和表的数目停止取模,余数是几就往哪张表中插入数据。
留意:子表中的id要与主表的id保持一致
今后只要插入操纵会用到主表,修改,删除,读取,均不需要用到主表
redis新闻队列
1,什么是新闻队列?
新闻传播历程中留存新闻的容器
2,新闻队列发生的历史缘由

新闻队列的特点:先进先出
把要施行的sql语句先留存在新闻队列中,然后顺次依照顺利异步插入的数据库中
利用:新浪,把瞬时的评论先放入新闻队列,然后通过按时任务把新闻队列里面的sql语句顺次插入到数据库中
修改
操纵子表停止修改
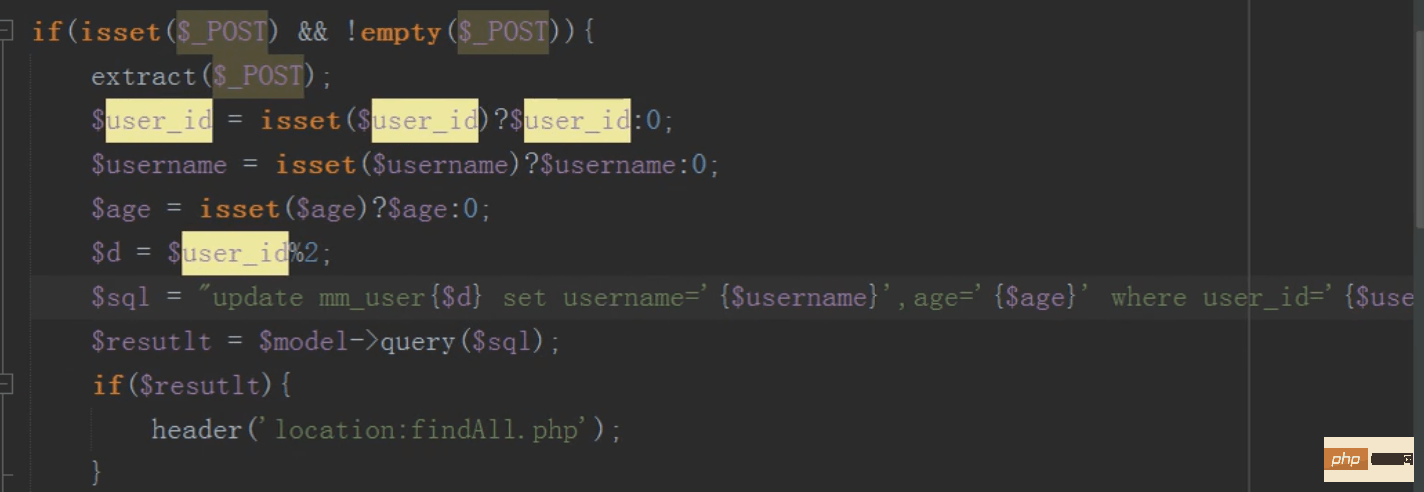
这样修改有一个问题,主表和子表的数据会显现不一致,怎样让主表和字表数据一致?
redis队列保持主表子表数据一致
修改完成后将要修改主表的数据,存入redis队列中
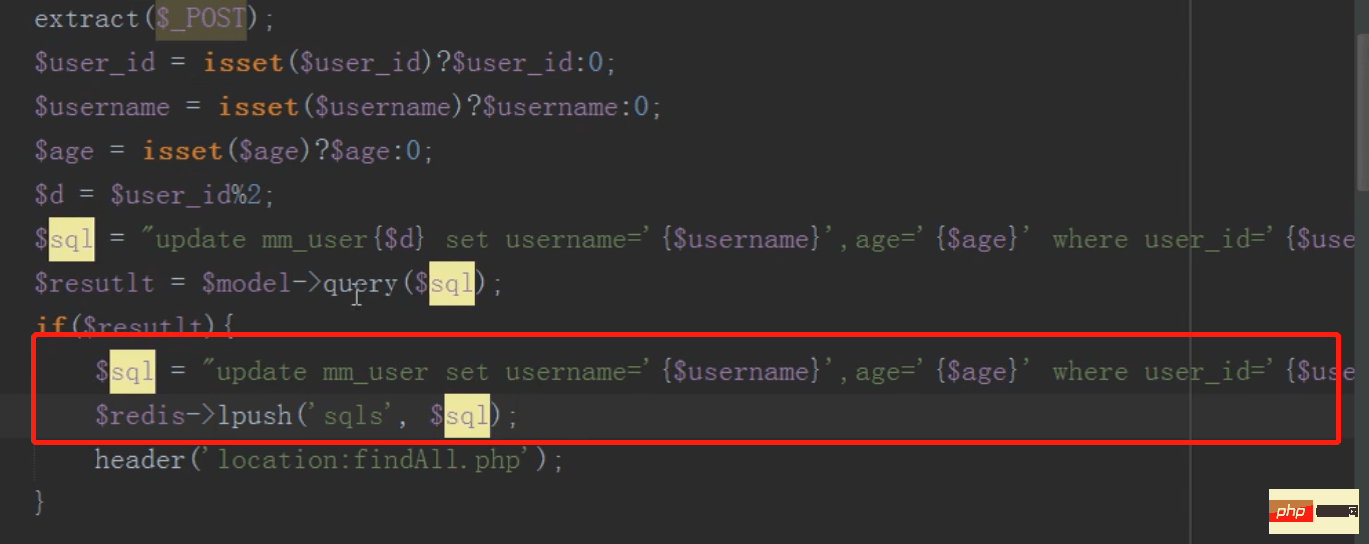
然后linux按时任务(contble)轮回施行redis队列中的sql语句,同步更新主表的内容

mysql分布式之分表(查,删)
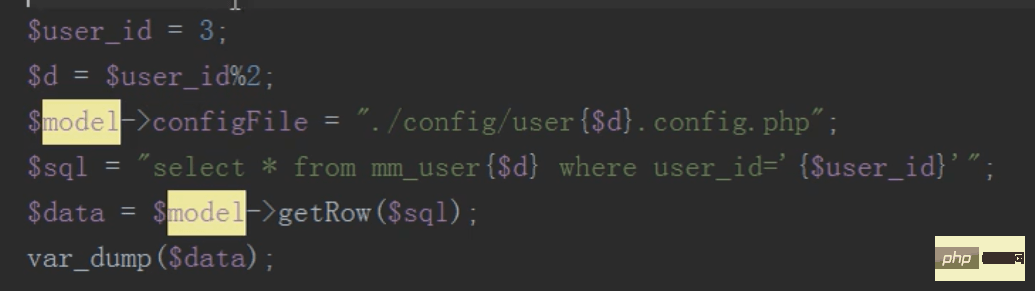
查询只需要查询子表,不要查询总表
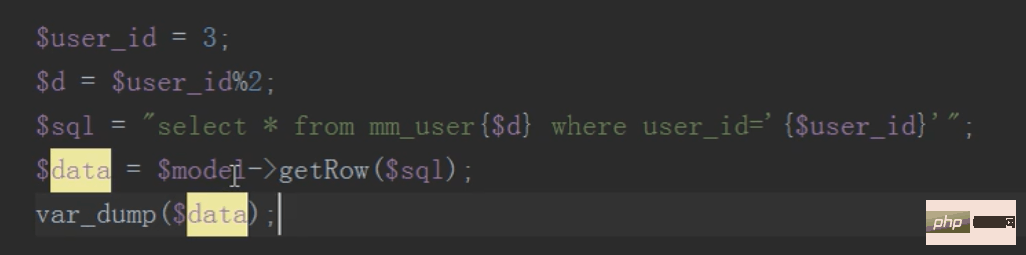
删除,先按照id寻到要删除的子表,然后删除,然后往新闻队列中压入一条删除总表数据的sql语句
然后施行按时任务删除总表数据

按时任务:
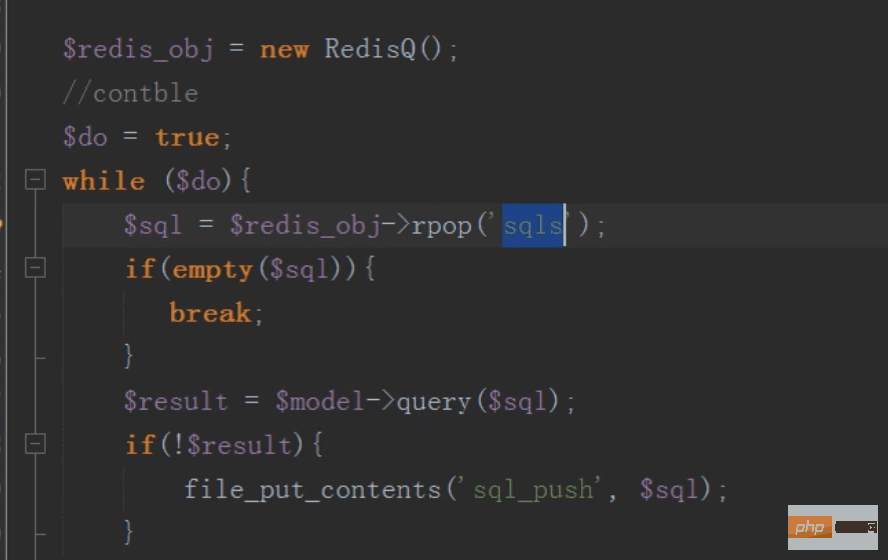
mysql分布式之分库
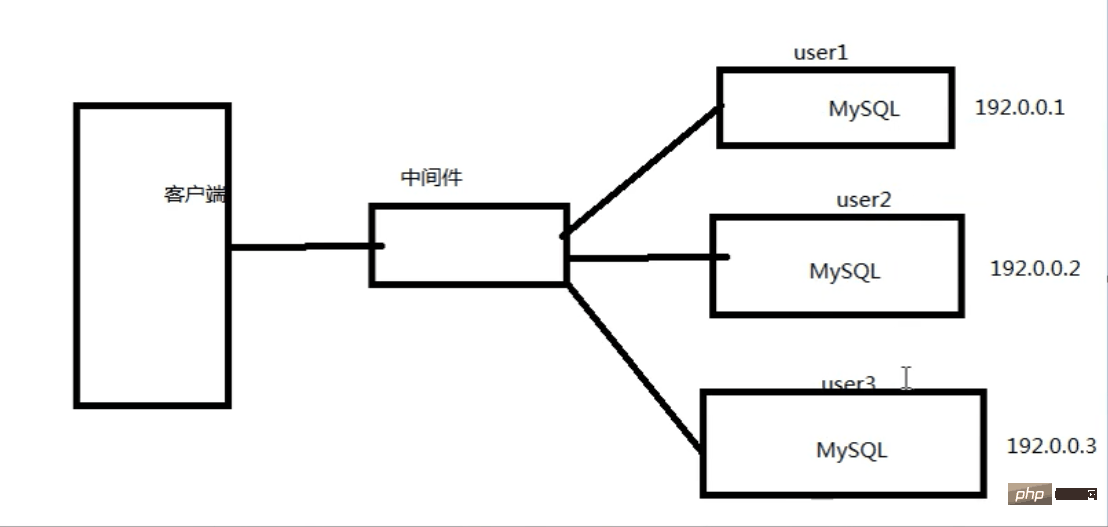
分库思绪

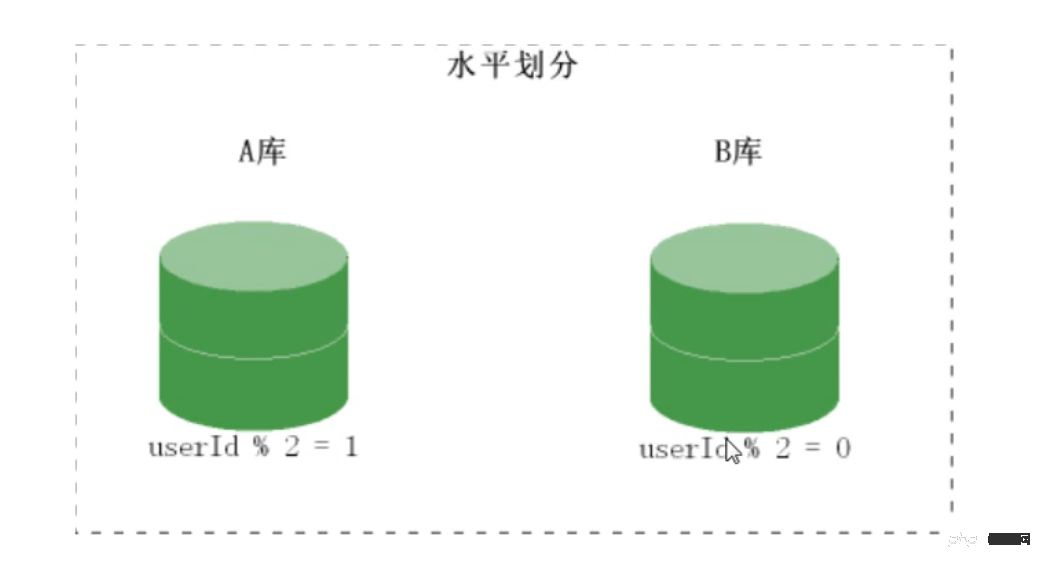
分库道理图:
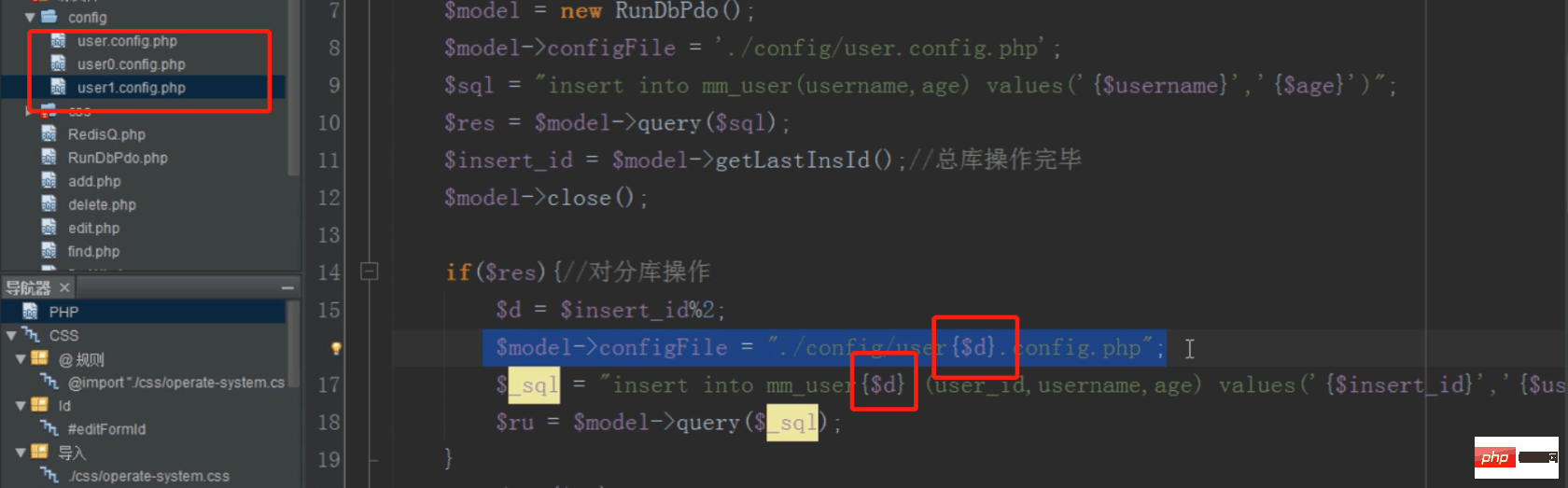
mysql分布式之分库(增)
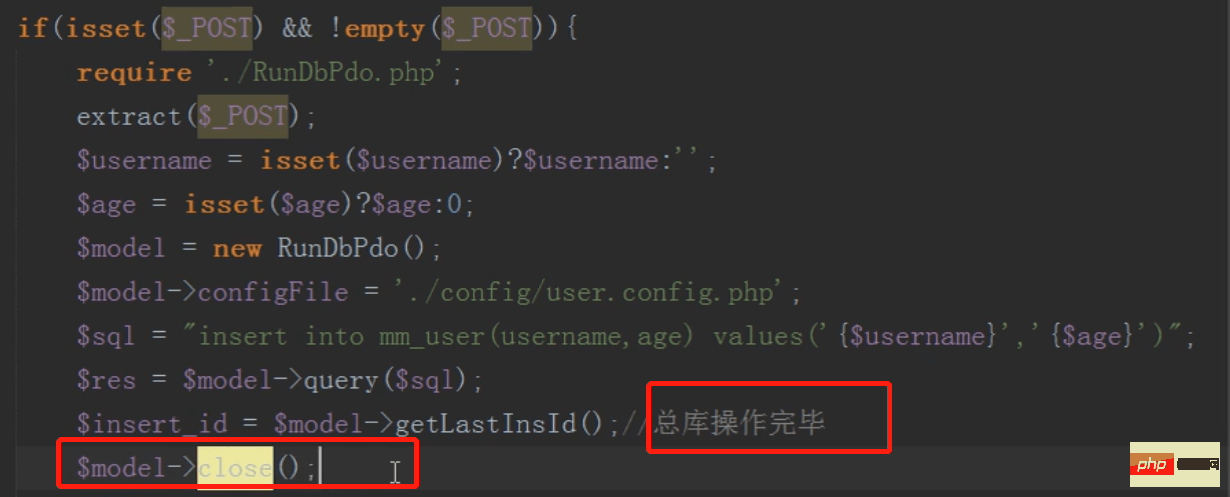
留意:操纵完一个数据库必然要把数据库连接关闭,不然mysql会认为不断连接的统一个数据库
还是取模肯定加载哪个配置文件连接哪个数据库
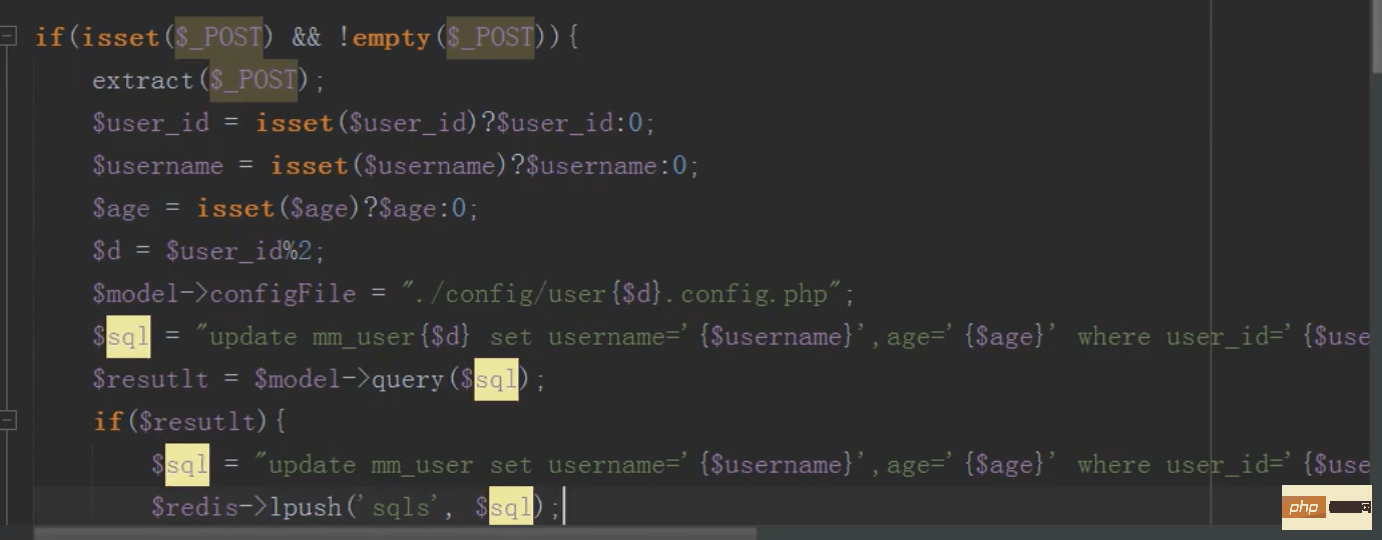
mysql分布式之分库(改)
道理同新增
mysql分布式之分库(查,删)
道理相似
删除
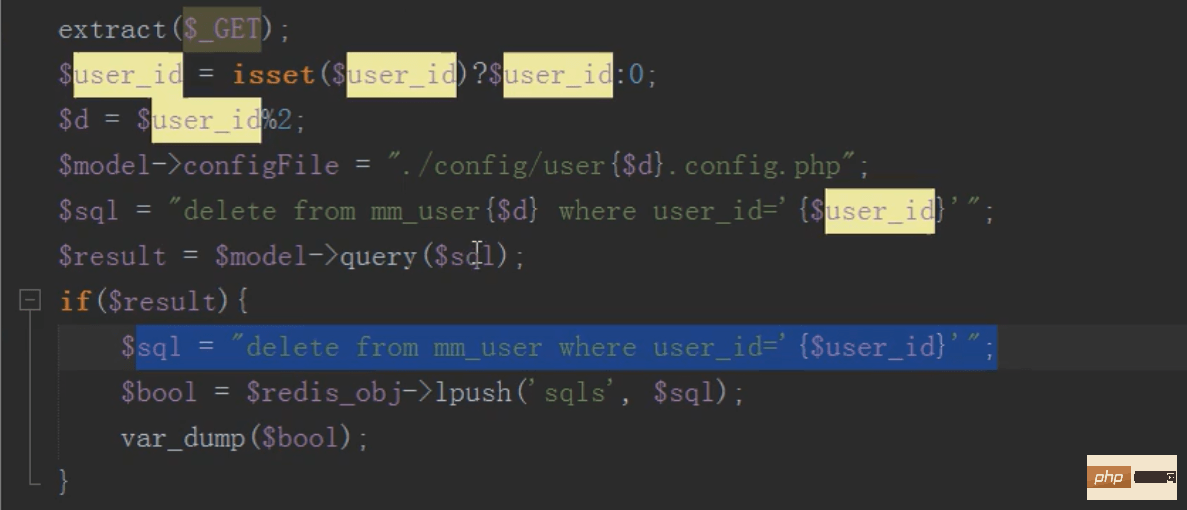
施行队列
mysql分布式之缓存(memcache)的利用
将数据放入缓存中,节约数据库开销,先去缓存中查,假如有直接取出,假如没有,去数据库查,然后存入缓存中
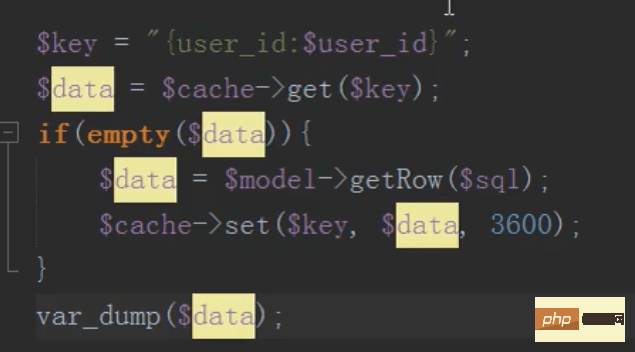
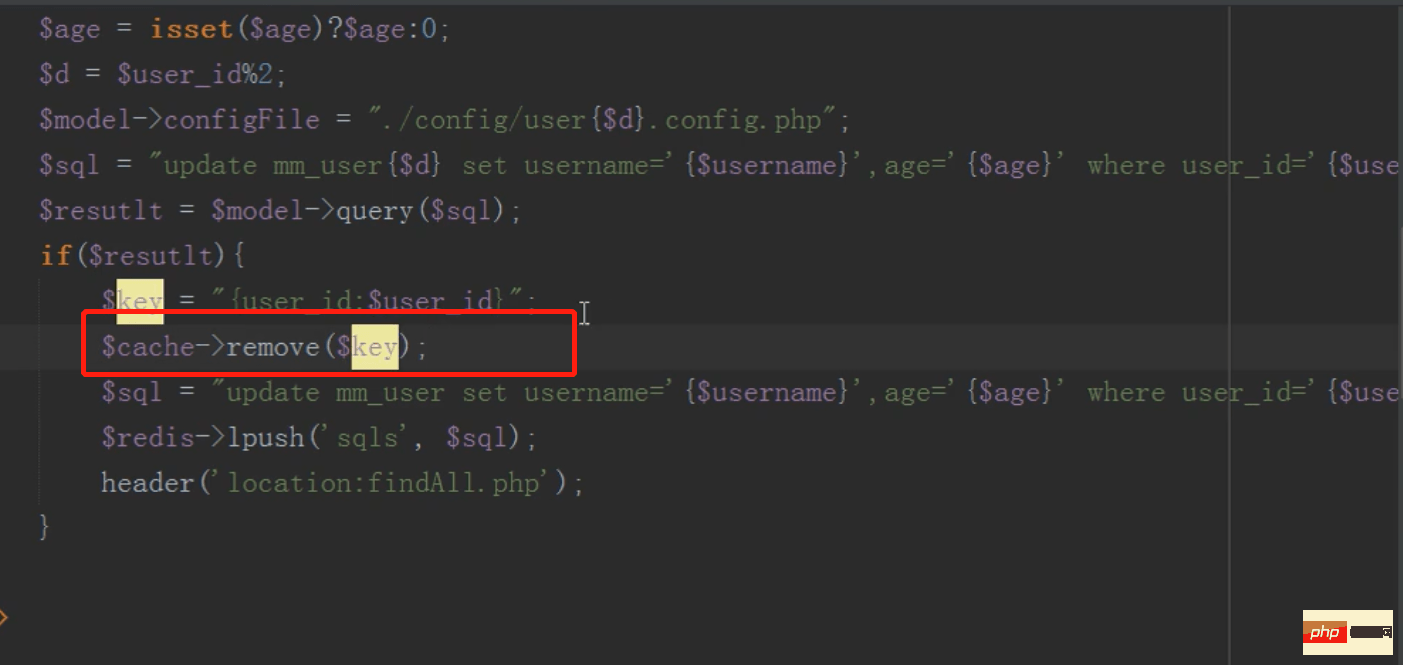
在编纂信息之后需要删除缓存,不然不断读取的是缓存的数据而不是修改正的数据
以上就是PHP结合MySQL实现千万级数据处置的具体内容,更多请关注百分百源码网其它相关文章!




