Linux服务器下搭建hadoop集群环境 redhat5/Ubuntu 12.04
Ubuntu 12.04 下搭建 hadoop 集群环境步骤
一. 搭建环境前的准备:
我的本机Ubuntu 12.04 32bit作为maser,就是上篇hadoop单机版环境搭建时用的那台机子,http://www.linuxidc.com/Linux/2013-01/78112.htm
还在KVM中虚拟了4台机子,分别起名为:
son-1 (ubuntu 12.04 32bit),
son-2 (ubuntu 12.04 32bit),
son-3 (CentOS 6.2 32bit),
son-4 (RedHat 6.0 32bit).
下来修改本机的host文件,
sudo gedit /etc/hosts
在后面添加内容为:
192.168.200.150 master
192.168.200.151 son-1
192.168.200.152 son-2
192.168.200.153 son-3
192.168.200.154 son-4
现在开始我们的打建之旅吧。
二 . 为本机(master)和子节点(son..)分别创建hadoop用户和用户组,其实ubuntu和centos下创建用户还多少还是有点区别的。
ubuntu下创建:
先创建hadoop用户组:
sudo addgroup hadoop
然后创建hadoop用户:
sudo adduser -ingroup hadoop hadoop
centos 和 redhat 下创建:
sudo adduser hadoop
注:在centos 和 redhat下直接创建用户就行,会自动生成相关的用户组和相关文件,而ubuntu下直接创建用户,创建的用户没有家目录。
给hadoop用户添加权限,打开/etc/sudoers文件;
sudo gedit /etc/sudoers
按回车键后就会打开/etc/sudoers文件了,给hadoop用户赋予root用户同样的权限。
在root ALL=(ALL:ALL) ALL下添加hadoop ALL=(ALL:ALL) ALL,
hadoop ALL=(ALL:ALL) ALL
三. 为本机(master)和子节点(son..)安装JDK环境。
ubuntu下一条命令即可:
sudo apt-get install openjdk-6-jre
centos和redhat建议下载源码安装。
四. 修改 本机(master)和子节点(son..)机器名
打开/etc/hostname文件;
sudo gedit /etc/hostname
分别修改为:master son-1 son-2 son-3 son-4。这样有利于管理和记忆!
五. 本机(master)和子节点(son..)安装ssh服务
主要为Ubuntu安装,cents和RedHat系统自带。
ubuntu下:
sudo apt-get install ssh openssh-server
这时假设您已经安装好了ssh,您就可以进行第六步了哦~
六. 先为建立ssh无密码登录环境
做这一步之前首先建议所有的机子全部转换为Hadoop用户,以防出现权限问题的干扰。
切换的命令为:
su - hadoop
ssh生成密钥有rsa和dsa两种生成方式,默认情况下采用rsa方式。
1. 创建ssh-key,,这里我们采用rsa方式;
ssh-keygen -t rsa -P ""
(注:回车后会在~/.ssh/下生成两个文件:id_rsa和id_rsa.pub这两个文件是成对出现的)
2. 进入~/.ssh/目录下,将id_rsa.pub追加到authorized_keys授权文件中,开始是没有authorized_keys文件的;
cd ~/.ssh
cat id_rsa.pub >> authorized_keys
七. 为本机mater安装hadoop
我们采用的hadoop版本是:hadoop-0.20.203(http://www.apache.org/dyn/closer.cgi/hadoop/common/ ),因为该版本比较稳定。
1. 假设hadoop-0.20.203.tar.gz在桌面,将它复制到安装目录 /usr/local/下;
sudo cp hadoop-0.20.203.0rc1.tar.gz /usr/local/
2. 解压hadoop-0.20.203.tar.gz;
cd /usr/local
sudo tar -zxf hadoop-0.20.203.0rc1.tar.gz
3. 将解压出的文件夹改名为hadoop;
sudo mv hadoop-0.20.203.0 hadoop
4. 将该hadoop文件夹的属主用户设为hadoop,
sudo chown -R hadoop:hadoop hadoop
5. 打开hadoop/conf/hadoop-env.sh文件;
sudo gedit hadoop/conf/hadoop-env.sh
6. 配置conf/hadoop-env.sh(找到#export JAVA_HOME=...,去掉#,然后加上本机jdk的路径);
export JAVA_HOME=/usr/lib/jvm/java-6-openjdk
7. 打开conf/core-site.xml文件;
sudo gedit hadoop/conf/core-site.xml
编辑如下:
<?xmlversion="1.0"?>
<?xml-stylesheettype="text/xsl"href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
8. 打开conf/mapred-site.xml文件;
sudo gedit hadoop/conf/mapred-site.xml
编辑如下:
<?xmlversion="1.0"?>
<?xml-stylesheettype="text/xsl"href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>master:9001</value>
</property>
</configuration>
9. 打开conf/hdfs-site.xml文件;
sudo gedit hadoop/conf/hdfs-site.xml
编辑如下:
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/usr/local/hadoop/datalog1,/usr/local/hadoop/datalog2</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/local/hadoop/data1,/usr/local/hadoop/data2</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
10. 打开conf/masters文件,添加作为secondarynamenode的主机名,这里需填写 master 就Ok了。
sudo gedit hadoop/conf/masters
11. 打开conf/slaves文件,添加作为slave的主机名,一行一个。
sudo gedit hadoop/conf/slaves
这里填成下列的内容 :
son-1
son-2
son-3
son-4
八. 要将master机器上的文件一一复制到datanode机器上(son-1,son-2,son-3,son-4都要复制):(这里以son-1为例子)
1. 公钥的复制
scp ~/.ssh/id_rsa.pub Hadoop@son-1:~/.ssh/
2. hosts文件的复制
scp /etc/hosts hadoop@son-1:/etc/hosts
注:这里如果不能复制,就先将文件复制到/home/hadoop下面,即为:
/home/hadoophadoop@son-1: scp /etc/hosts
再在datanode机器上将其移到相同的路径下面/etc/hosts .
3. hadoop文件夹的复制,其中的配置也就一起复制过来了!
scp -r /usr/local/hadoop hadoop@son-1:/usr/local
如果不能移动的话和上面的方法一样!
并且要将所有节点的hadoop的目录的权限进行如下的修改:
sudo chown -R hadoop:hadoop hadoop
这些东西都复制完了之后,datanode机器还要将复制过来的公钥追加到收信任列表:
在每个子节点的自己种都要操作。
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
还有很重要的一点,子节点datanode机器要把复制过来的hadoop里面的data1,data2和logs删除掉!
还有要修改CentOS节点(son-3)和RedHat节点(son-4)的java的环境变量地址,
配置centos节点(son-3)和redhat节点(son-4)的/usr/local/hadoop/conf/hadoop-env.sh(找到#export JAVA_HOME=...,去掉#,然后加上本机jdk的路径);这个环境不一,自己配置一下。
这样环境已经基本搭建好了,现在开始测试一下。
九. 这样之后基本上就差不多了,首先进入master的Hadoop目录。
cd /usr/local/hadoop
首先可以做一下负载平衡,我担心这个加上会有点乱,但是没有这部分不影响运行,想了解的给我留言!
启动datanode和tasktracker:
bin/start-dfs.sh
bin/hadoop-daemon.sh start datanode
bin/hadoop-daemon.sh start tasktracker
启动全部服务直接一条命令:
bin/start-all.sh
查看自己的datanode是否启动.
jps
当jps不能正常使用的时候:
resource /etc/profile
连接时可以在namenode上查看连接情况:
bin/hadoop dfsadmin -report
详见下图:
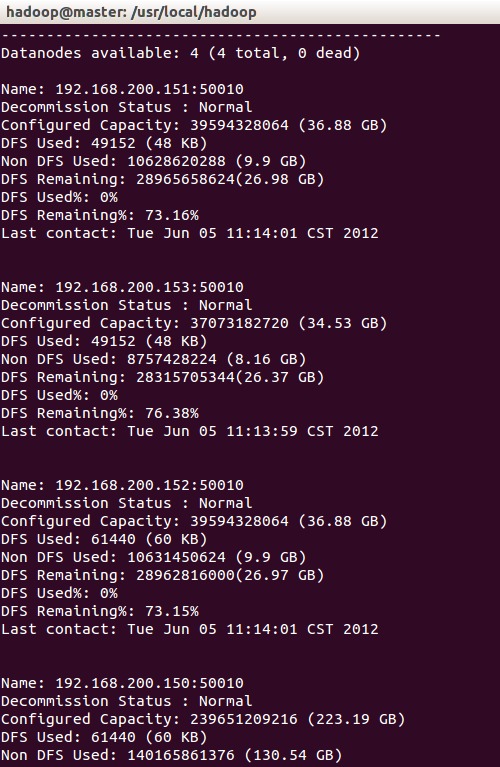
也可以直接进入网址:
master:50070
详见下图:
图1:
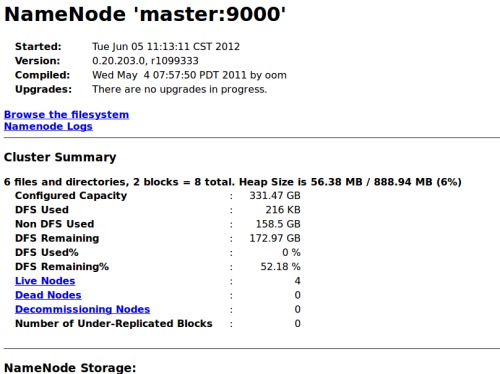
图2:
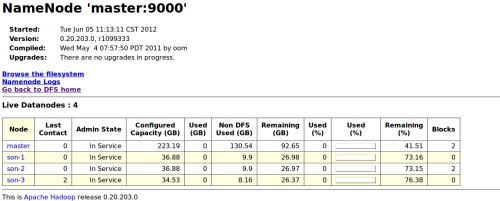
因为readhat的java环境还有点问题所以没有启动起来,其它的正常。
切记,上面的大多数操作请使用hadoop用户,要不然中间会出许多关于权限的问题。
到此整个环境的搭建工作就完成了。
redhat5下搭建hadoop集群环境步骤
前期准备
两台linux虚拟机(本文使用redhat5,IP分别为 192.168.1.210、192.168.1.211)
JDK环境(本文使用jdk1.6,网上很多配置方法,本文省略)
Hadoop安装包(本文使用Hadoop1.0.4)
搭建目标
210作为主机和节点机,211作为节点机。
搭建步骤
1修改hosts文件
在/etc/hosts中增加:
在/etc/hosts中增加:
192.168.1.210 hadoop1
192.168.1.211 hadoop2
2 实现ssh无密码登陆
2.1 主机(master)无密码本机登录
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
直接回车,完成后会在 ~/.ssh/ 生成两个文件: id_dsa 和 id_dsa.pub 。这两个是成对出现,类似钥匙和锁。
再把 id_dsa.pub 追加到授权 key 里面 ( 当前并没有 authorized_key s文件 ) :
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
实验:
ssh localhost hostname
还是要输入密码,一般这种情况都是因为目录或文件的权限问题,看看系统日志,确实是权限问题,
.ssh下的authorized_keys权限为600,其父目录和祖父目录应为755
2.2 无密码登陆节点机(slave)
slave上执行:
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
生成.ssh目录。
将master上的authorized_keys复制到slave上:
scp authorized_keys hadoop2:~/.ssh/
实验:在master上执行
ssh hadoop2
实现无密码登陆。
3 配置Hadoop
3.1拷贝hadoop
将hadoop-1.0.4.tar.gz ,拷贝到usr/local 文件夹下,然后解压。
解压命令:
tar ?zxvf hadoop-1.0.4.tar.gz
3.2查看 cat /etc/hosts
192.168.1.210 hadoop1
192.168.1.211 hadoop2
3.3 配置 conf/masters 和 conf/slaves
conf/masters:
192.168.1.210
conf/slaves:
192.168.1.211
192.168.1.211
3.4 配置 conf/hadoop-env.sh
加入
export JAVA_HOME=/home/elvis/softk1.7.0_17
3.5 配置 conf/core-site.xml
加入
<property>
<name>fs.default.name</name>
<value>hdfs://192.168.1.210:9000<alue>
</property>
3.6 配置 confLinux服务器下搭建hadoop集群环境fs-site.xml
加入
<property>
<name>dfs.http.address</name>
<value>192.168.1.210:50070<alue>
</property>
<property>
<name>dfs.name.dir</name>
<value>/usr/local/hadoop/namenode<alue>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/local/hadoop/data<alue>
</property>
<property>
<name>dfs.replication</name>
<value>2<alue>
</property>
3.7 配置conf/mapred-site.xml
加入
<property>
<name>mapred.job.tracker</name>
<value>192.168.1.50:8012<alue>
</property>
3.8 建立相关的目录
/usr/local/hadoop/ //hadoop数据和namenode目录
【注意】只创建到hadoop目录即可,不要手动创建data和namenode目录。
其他节点机也同样建立该目录。
3.9 拷贝hadoop文件到其他节点机
将hadoop文件远程copy到其他节点(这样前面的配置就都映射到了其他节点上),
命令:
scp -r hadoop-1.0.4 192.168.1.211:/usr/local/
3.10 格式化Active master(192.168.201.11)
命令:
bin/hadoop namenode -format
3.11 启动集群 ./start-all.sh
现在集群启动起来了,看一下,命令:
bin/hadoop dfsadmin -report
2个datanode,打开web看一下
浏览器输入:192.168.1.210:50070
打完收工,集群安装完成!
常见问题
1 Bad connection to FS. command aborted
需要查看日志,我的日志中显示:
2013-06-09 15:56:39,790 ERROR org.apache.hadoop.hdfs.server.namenode.NameNode: java.io.IOException: NameNode is not formatted.
at org.apache.hadoop.hdfs.server.namenode.FSImage.recoverTransitionRead(FSImage.java:330)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.loadFSImage(FSDirectory.java:100)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.initialize(FSNamesystem.java:388)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.<init>(FSNamesystem.java:362)
at org.apache.hadoop.hdfs.server.namenode.NameNode.initialize(NameNode.java:276)
at org.apache.hadoop.hdfs.server.namenode.NameNode.<init>(NameNode.java:496)
at org.apache.hadoop.hdfs.server.namenode.NameNode.createNameNode(NameNode.java:1279)
at org.apache.hadoop.hdfs.server.namenode.NameNode.main(NameNode.java:1288)
NameNode没被格式化!!!
解决办法:
原因是我手动建了 /usr/local/hadoop/data 和 /usr/local/hadoop/namenode,把这两个目录删除重新格式化namenode即可。
2 WARN org.apache.hadoop.hdfs.server.datanode.DataNode: Invalid directory in dfs.data.dir: Incorrect permission for /usr/local/hadoop/data, expected: rwxr-xr-x, while actual: rwxrwxrwx
解决办法:
/usr/local/hadoop/目录权限过高,改成chmod 755即可。
3 eclipse插件问题
异常1:2011-08-03 17:52:26,244 INFO org.apache.hadoop.ipc.Server: IPC Server handler 6 on 9800, call getListing(/home/fish/tmp20/mapred/system) from 192.168.2.101:2936: error: org.apache.hadoop.security.AccessControlException: Permission denied: user=DrWho, access=READ_EXECUTE, inode=”system”:root:supergroup:rwx-wx-wx
org.apache.hadoop.security.AccessControlException: Permission denied: user=DrWho, access=READ_EXECUTE, inode=”system”:root:supergroup:rwx-wx-wx
at org.apache.hadoop.hdfs.server.namenode.PermissionChecker.check(PermissionChecker.java:176)
at org.apache.hadoop.hdfs.server.namenode.PermissionChecker.checkPermission(PermissionChecker.java:111)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkPermission(FSNamesystem.java:4514)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkPathAccess(FSNamesystem.java:4474)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getListing(FSNamesystem.java:1989)
at org.apache.hadoop.hdfs.server.namenode.NameNode.getListing(NameNode.java:556)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:39)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:25)
at java.lang.reflect.Method.invoke(Method.java:597)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:508)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:959)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:955)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:396)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:953)
解决方法:在hdfs-site.xml里加入下面的
<property>
<name>dfs.permissions</name>
<value>false<alue>
</property>
HDFS常用命令
创建文件夹
./hadoop fs ?mkdir /usr/local/hadoop/godlike
上传文件
./hadoop fs ?put/copyFromLocal 1.txt /usr/local/hadoop/godlike
查看文件夹里有哪些文件
./hadoop fs ?ls /usr/local/hadoop/godlike
查看文件内容
./hadoop fs ?cat/text/tail /usr/local/hadoop/godlike/1.txt
删除文件
./hadoop fs ?rm /usr/local/hadoop/godlike
删除文件夹
./hadoop fs ?rmr /usr/local/hadoop/godlike




