MySQL查询反复数据(删除反复数据保存id最小的一条为独一数据)
发布时间:05/13 来源:未知 浏览:
关键词:
开发背景:
最近在做一个批量数据导入到MySQL数据库的功能,从批量导入就可以晓得,这样的数据在插入数据库以前是不会进行反复判断的,因而只要在全部数据导入进去今后在施行一条语句进行删除,保证数据独一性。
下面话不多说了,来一起看看细致的介绍吧
实战:
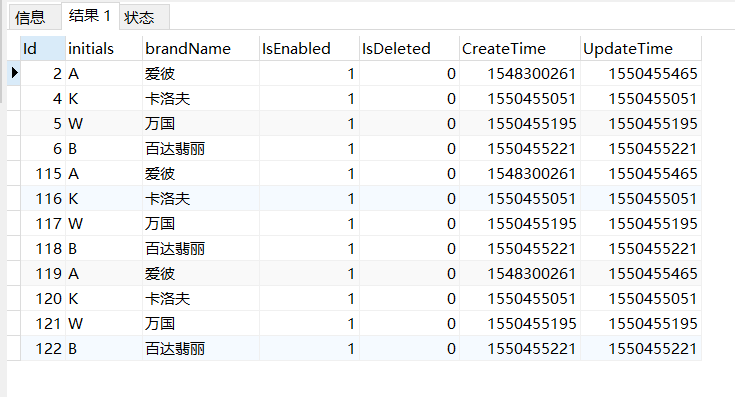
表构造如下图所示:
表明:brand
操纵:
运用SQL语句查询反复的数据有哪些:
SELECT * from brand WHERE brandName IN( select brandName from brand GROUP BY brandName HAVING COUNT(brandName)>1 #前提是数目大于1的反复数据 )
运用SQL删除多余的反复数据,并保存Id最小的一条独一数据:
注意点:
差错SQL:DELETE FROM brand WHERE brandName IN (select brandName from brand GROUP BY brandName HAVING COUNT(brandName)>1)
AND Id NOT IN (select MIN(Id) from brand GROUP BY brandName HAVING COUNT(brandName)>1)
提醒: You can't specify target table 'brand' for update in FROM clause 不能为FROM子句中的更新指定指标表“brand”
缘由是:不能将直接查处来的数据当做删除数据的前提,我们应当先把查出来的数据新建一个临时表,然后再把临时表作为前提进行删除功能
准确SQL写法: DELETE FROM brand WHERE brandName IN (SELECT brandName FROM (SELECT brandName FROM brand GROUP BY brandName HAVING COUNT(brandName)>1) e) AND Id NOT IN (SELECT Id FROM (SELECT MIN(Id) AS Id FROM brand GROUP BY brandName HAVING COUNT(brandName)>1) t) #查询显示反复的数据都是显示最前面的几条,因而不需要查询是否最小值
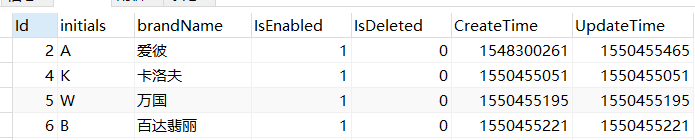
效果如下图:
总结:
许多东西都是需要本人一步一步的去探讨的,当然网上的倡议也是非常宝贵的借鉴和资源,不管做什么开发我们都需要了解它的工作道理才能够更好的把握它。
好了,以上就是这篇文章的全部内容了,但愿本文的内容对大家的学习或者工作拥有一定的参考学习价值,要是有疑难大家可以留言交换,感谢大家对脚本之家的支撑。




